
SaaSは利用料が高いのでOSSを使う
サーバのログを可視化するSaaSは沢山あり、手軽にBusiness Intelligenceを施行できます。
DataDogとかKeen IOとかlibrato、Logglyなどなど。
とても便利そうですね。でも価格が高い!
なんでもかんでもSaaSに頼ってたら毎月数十万とかになりそうです。貧乏にはつらいです。
だから、OSSで無料でやりましょう。
もちろんインフラ代は最低限かかります。
でも、クラウドリソースはいずれ水みたいになりますから、そこはしばらくの辛抱です。
要件
独自フォーマットのログを扱いたい
今回はApacheのアクセスログみたいな一般的なものではなく、独自のアプリケーションログを集積して可視化します。
ログデータのフォーマットは以下のようなイメージです:
{
"logid": "Log ID",
"level": "Log level (DBG/MSG/WRN/ERR)",
"message": "Message",
"module": "Name of the application module",
"hostname": "Hostname sent the log",
"time": "timestamp of the log",
<Further data..>
}
このフォーマットは昔に設計したもので、解析するのを意識していなかった事情があります。
アプリケーション特化の情報も一緒に格納したい
上記フォーマットに書いてある<further data..>の部分は、アプリケーション特化の情報です。
エラーログならコールスタックとか、ユーザ登録ならユーザIDとかです。
そういう特別な情報は、可視化までしなくとも個別に見られるようにしておきたい。
また、今回の構成が将来的に変更になっても対応しやすいように、フォーマットをシステム特化で縛りたくない。
グラフ設定を簡単に柔軟に変えられるようにしたい
Graphiteとかすごく良いんですが、細かい調整がやりにくい。
タイムスケールをもうちょっと細かくみたいな、とか、ヒストグラムの分割単位を変えたいとか、そこはパイグラフで見たいとか、トレンドで見たいとか、このシリーズだけ抜き出したいとか。
あと、上記でも挙げた特化データを個別にすぐ表示できると便利です。
GrowthForecastもいいんだけど、イマドキRRDtoolかよ・・JSでグリグリ動くのがいい。
システム構成
上記の要件を満たす構成は、以下のようなイメージです。
タイトルの通り、fluentd + MongoDB + Elasticsearch + Kibanaとなりました。

以下、それぞれ概要と用途を説明します。
fluentd
ログ集積のためのツール。
PHP/node.js/Ruby/Python製などのさまざまなプログラムと連携させられます。
syslogやApache/nginxログにも対応。
それらのログを集めて、フィルタリングしたり整形した後、集積先へと転送してくれます。
MongoDB
NOSQLのDBMSです。
構造体のデータを格納できます。
スキーマレスなので、アプリケーション特化の情報をどんどん追加格納できます。
Capped collectionで高速にログを蓄積できます。
今回は、ログの一次格納先として使用します。
のちのち可視化部分のシステム構成が変更になった場合に、元のデータをオリジナルで保持しておけば対応がいくらか容易になるからです。
Elasticsearch
Luceneベースの全文検索サーバ。
MongoDBと同じく、スキーマレスで構造体が扱えます。
MongoDBからデータを流し込んで、可視化用にインデックスを作成してくれます。
Kibana
タイムスタンプがついたデータならなんでも可視化できるというツール。
Elasticsearchと密結合になっています。
UIがよくできていて、柔軟に設定を変えられるので、今回の用途にもってこいです。
Chefを使ったセットアップ手順
基本的にサーバはChefで管理したいので、Cookbookを拾ってきて使います。
以下を前提に進めます
- MongoDBサーバはすでに立ててある
- サーバはDebian/Ubuntu
- インフラはEC2
手順内にsspeと出てきますが、プロジェクトのコードネームです。
ご自身のプロジェクト名と読み替えてください。
fluentdの設定
アプリケーションは、td-agent(fluentd agent)に対してhttp経由でログを投げます。
td-agentは、受け取ったログを指定のmongodbに転送します。
mongodbはreplicasetなので、typeをmongo_replsetとしています。
<source>
type http
port 8888
</source>
<match sspe.log.*>
type mongo_replset
database fluent
collection log
# Following attibutes are optional
nodes mongodb-server-1:27017,mongodb-server-2:27017
# Set 'capped' if you want to use capped collection
capped
capped_size 1000m
# Other buffer configurations here
flush_interval 10s
</match>
ElasticsearchとKibanaのインストール
1つのサーバにElasticsearchとKibanaの両方を入れます。
Elasticsearchには、以下の4つのプラグインもインストールします。
- elasticsearch-mapper-attachments
- elasticsearch-river-mongodbから依存
- GridFSを取り扱うためのもの
- elasticsearch-river-mongodb
- MongoDBからElasticsearchにデータを流し込むためのもの
- elasticsearch-head
- 簡易管理UI
- elasticsearch-HQ
- headよりリッチな管理UI
まずはEC2ノードを立てる
Knifeコマンドでサクっと立てます。
- OS: Ubuntu Server 14.04 LTS (HVM), SSD Volume Type
$ knife ec2 server create
-I ami-a1124fa0
-f t2.small
--node-name server-name
--security-group-ids sg-hogehoge
--subnet subnet-111111111
--associate-public-ip
--ebs-size 50
--ssh-key ssh-key-name
--identity-file ~/.ssh/id_rsa
--ssh-user ubuntu
--ssh-gateway ubuntu@hogehuga
--verbose
CookbookをChef serverにアップロードする
Berksfileに以下の行を追記します。
cookbook 'elasticsearch'
cookbook 'java'
cookbook 'kibana', git: 'git@github.com:lusis/chef-kibana.git'
なぜかKibanaだけ同名の想定とは別のものが入ってしまったので、repos uriを指定します。
インストールしてアップロードします。
$ berks install
$ berks upload
Chefノードを設定する
ノードの設定を編集します。
$ knife node edit server-name
{
"name": "server-name",
"chef_environment": "_default",
"normal": {
"tags": [
],
"java": {
"install_flavor": "openjdk",
"jdk_version": "7"
},
"elasticsearch": {
"version": "1.2.2",
"cluster": {
"name": "sspe"
},
"plugins": {
"elasticsearch/elasticsearch-mapper-attachments": {
"version": "2.3.0"
},
"com.github.richardwilly98.elasticsearch/elasticsearch-river-mongodb": {
"version": "2.0.1"
},
"mobz/elasticsearch-head": {
},
"royrusso/elasticsearch-HQ": {
},
"elasticsearch/elasticsearch-lang-javascript": {
"version": "2.1.0"
}
}
},
"kibana": {
"config": {
"elasticsearch": "window.location.protocol+"//"+window.location.hostname+":"+9200",
"default_route": "/dashboard/file/guided.json"
},
"kibana": {
"web_dir": "/opt/kibana/current"
}
},
},
"run_list": [
"recipe[java]",
"recipe[elasticsearch]",
"recipe[elasticsearch::plugins]",
"recipe[kibana::install]"
]
}
設定出来たら、chef-clientを実行します。
動作確認
以下のように結果が返ってきたら成功です。
$ curl "http://localhost:9200/_cluster/health?pretty"
{
"cluster_name" : "sspe",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0
}
Elasticsearchの設定
インデックスの作成
Elasticsearchのインデックスとは、RDBMSでいうデータベースみたいなもんです。
下記コマンドで作成します。
curl -XPUT 'http://localhost:9200/sspe/'
マッピングの作成
マッピングとは、RDBMSにおけるスキーマ定義みたいなもんです。
明示しなくても自動で作成させる事もできますが、今回は勉強も兼ねて指定します。
$ curl -XPUT 'http://localhost:9200/sspe/log/_mapping' -d '
{
"log" : {
"properties" : {
"logid" : {"type" : "string" },
"level" : {"type" : "string" },
"message" : {"type" : "string", "store" : true },
"module" : {"type" : "string" },
"hostname" : {"type" : "string" },
"time" : {"type" : "date" },
"userinfo": { "type": "object", "enabled": false, "include_in_all": true }
}
}
}
'
MongoDB riverの設定
riverとは、Elasticsearchにデータを流し込む経路設定のことです。
elasticsearch-river-mongodbをインストールしてあるので、これを使う設定をします。
$ curl -XPUT "localhost:9200/_river/mongodb/_meta" -d '
{
"type": "mongodb",
"mongodb": {
"servers":
[
{ "host": "mongodb-server-1", "port": 27017 },
{ "host": "mongodb-server-2", "port": 27017 }
],
"options": {
"secondary_read_preference" : true
},
"db": "fluent",
"collection": "log"
},
"index": {
"name": "sspe",
"type": "log"
}
}'
実行すると、データの抽出が開始されるはずです。
データの流入確認
下記URLから、headプラグインの管理画面を開きます。
http://<elasticsearch-server>:9200/_plugin/head/

ドキュメント数が増えていれば成功です。
トラブルシューティング
Cannot start river mongodb. Current status is INITIAL_IMPORT_FAILED
もし設定がうまく動かなくて、Elasticsearchを再起動してもログに上記が吐かれて止まってしまう場合。
Riverのステータスをリセットしてやれば再稼働します。
$ curl -XDELETE 'http://localhost:9200/_river/mongodb/_riverstatus'
実行後、Elasticsearchを再起動します。
Kibanaの設定
ElasticSearchとの連動確認
ESとKibanaをインストールしたサーバにブラウザからアクセスします。
http://<elasticsearch-server>/#/dashboard/file/guided.json
すると、下記のような画面が表示されるはずです。

自分用のダッシュボードを設定する
以下にアクセスすると、空っぽのダッシュボードにアクセスできます。
http://<elasticsearch-server>/#/dashboard/file/blank.json
ADD A ROWというボタンをクリックして、グラフを表示する領域の行を追加します。

Rowの名前を入力後、Create Rowします。

次に、パネルを追加します。


- パネルタイプをhistogramにします
- 幅を12に設定
- タイムフィールドに
timeを指定 - Auto-intervalのチェックを外す
- Saveボタンをクリック
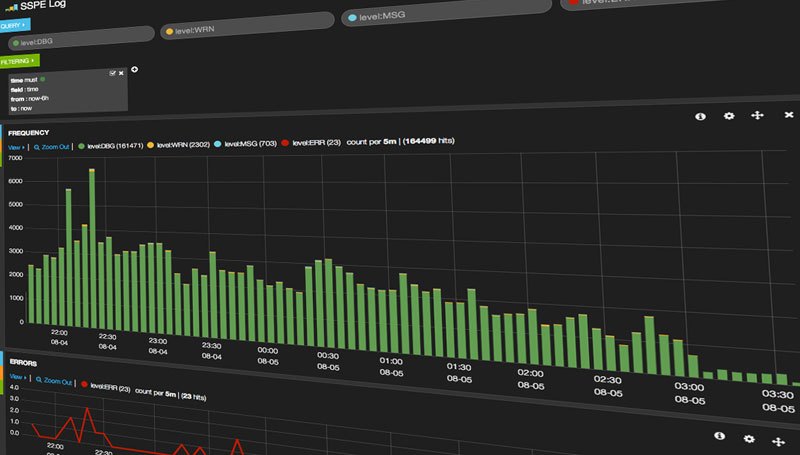
すると・・・

やった!出ましたね!
エラーログのみを表示したい場合は、QUERYの欄に level:ERR と打ちます。
クエリ構文はLuceneと基本同じものが使えるようです。以下が参考になります。

“fluentd + MongoDB + Elasticsearch + Kibanaでログを可視化する” への 1 件のフィードバック